
Un artículo publicado este fin de semana por Apple propone una cuantificación de las capacidades de razonamiento de los LLM, que parecen colapsar más allá de un cierto nivel de complejidad de las tareas. Varios observadores hablan de un duro golpe, un muro de complejidad con el que se enfrenta la actual generación de grandes modelos de lenguaje (LLM). 1 ¿Qué opina?
No se trata de un simple golpe duro, sino de un golpe de gracia, sobre todo porque este artículo no es un caso aislado. Es la continuación de otra investigación publicada el año pasado por varios de los mismos autores, que ya demostraba que es imposible construir agentes fiables sin un razonamiento formal y abstracto suficientemente desarrollado. 2
¿Podría resumir brevemente el argumento del artículo?
Apple ha probado las capacidades de «razonamiento» de las inteligencias artificiales actuales, como ChatGPT, Claude o DeepSeek. Si bien todos estos modelos parecen inteligentes a primera vista, fracasan por completo en cuanto aumenta la complejidad. La fuerza global del argumento es innegable: aunque hay una debilidad interesante en el nuevo razonamiento, la conclusión es inequívoca.
Ninguno de los modelos basados en LLM muestra un razonamiento verdadero. Se trata simplemente de sistemas de reconocimiento de patrones extremadamente costosos que se derrumban en cuanto se enfrentan a situaciones fuera de su ámbito de entrenamiento.
¿Se trata de un callejón sin salida estructural de los LLM para determinadas aplicaciones?
De hecho, todas las investigaciones serias demuestran ahora que los grandes modelos de lenguaje no razonan de la misma manera que los humanos. Pueden «pensar más», pero solo hasta cierto punto.
Más allá de un umbral determinado, se rinden rápidamente, incluso si aún disponen de recursos computacionales más que suficientes.
Ninguno de los modelos basados en MLL muestra un razonamiento verdadero.
Gary Marcus
Incluso cuando se les proporciona el algoritmo exacto a seguir —las reglas para resolver una tarea compleja—, estos modelos tienden a ejecutarlo muy mal. Esto pone de relieve una distinción esencial: ejecutar no significa comprender.
El problema no radica en la falta de creatividad, sino en un fallo lógico fundamental. Los modelos tienden a «pensar demasiado» en problemas sencillos y a probar respuestas erróneas incluso después de haber encontrado la correcta. Y ante problemas más difíciles, piensan menos. El resultado es un desperdicio de recursos informáticos por un lado y un abandono prematuro por otro.
¿Cómo encaja, en su opinión, este nuevo estudio —que prolonga el análisis crítico del paradigma actual que ya publicamos en 2023 en nuestras páginas— en el debate sobre la capacidad de los LLM para generalizar a situaciones radicalmente nuevas?
Por un lado, esta investigación hace eco y amplía el argumento sobre la distribución del entrenamiento que vengo desarrollando desde 1998: las redes neuronales, en diversas formas, pueden generalizar dentro de la distribución de datos con la que han sido entrenadas, pero sus generalizaciones tienden a colapsar fuera de esa distribución.
Este era el núcleo de un artículo que publiqué en 1998, en el que criticaba los perceptrones multicapa (multilayer perceptrons), los antecesores de los modelos de lenguaje actuales, mostrando sus fallos fuera de la distribución en tareas sencillas de cálculo y predicción de frases. 3
Existe una distinción esencial en la IA generativa: ejecutar no significa comprender.
Gary Marcus
Este fue también el eje central de mi primer libro, The Algebraic Mind (2001), 4 que ampliaba esta crítica, así como de mi primer artículo en Science (1999), 5 donde demostré, mediante un experimento, que los bebés de siete meses podían extrapolar de una manera que las redes neuronales de la época eran incapaces de replicar. Esta fue también la motivación principal de Deep Learning: Critical Appraisal (2018) 6 y, posteriormente, de Deep Learning is Hitting a Wall (2022). 7 El año pasado identifiqué esta limitación como la debilidad más importante —y la más importante de comprender— de los LLM.
Así que llevo bastante tiempo trabajando en este tema…
El artículo también se basa en el trabajo de Subbarao Kambhampati, investigador informático de la Universidad Estatal de Arizona.
Sí, y quiero subrayarlo. Esta investigación no solo hace eco de los argumentos que Rao lleva desarrollando desde hace varios años, sino que los refuerza.
Se trata de las críticas a los modelos denominados de «razonamiento» y las famosas «cadenas de pensamiento» (CoT) que producen, que parecen mucho menos sólidas de lo que se afirma.
Para quienes no estén familiarizados con el concepto, una «cadena de pensamiento» es, a grandes rasgos, lo que el sistema pretende haber «razonado» para llegar a una respuesta, en los casos en que realiza varios pasos de reflexión. Los «modelos de razonamiento», por su parte, se refieren a la nueva generación de intentos de eludir las limitaciones estructurales de los LLM, obligándolos a «razonar» en el tiempo, mediante una técnica denominada inference-time compute (cálculo en el momento de la inferencia).
Rao nunca ha estado convencido de este argumento.
Escribió una serie de brillantes artículos en los que demostraba, entre otras cosas, que las cadenas de pensamiento generadas por los LLM no siempre se corresponden con lo que estos modelos hacen realmente. Recientemente, por ejemplo, observó que tendemos a antropomorfizar en exceso los rastros de razonamiento de los LLM, hablando de «pensamiento» cuando este término no parece adecuado. 8
Otro de sus artículos recientes muestra que, incluso cuando las cadenas de razonamiento parecen correctas, las respuestas finales no siempre lo son. 9
De hecho, Rao fue sin duda el primero en demostrar que uno de estos «modelos de razonamiento» —en este caso, o1— adolecía del tipo de problema que documenta hoy el informe de Apple. 10 Recomiendo a todo el mundo que lea su trabajo.
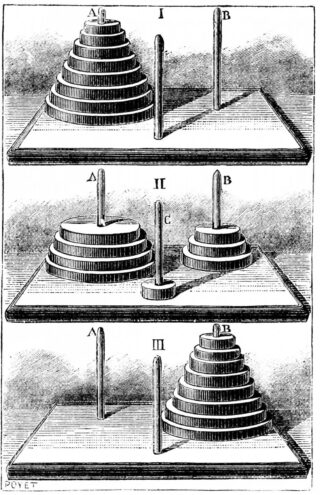
El documento de Apple retoma la crítica de Rao y la suya, centrándose en particular en un problema clásico bastante sencillo: la torre de Hanoi. ¿De qué se trata?
Se trata de un juego clásico compuesto por tres varillas y varios discos de diferentes tamaños. 11 El objetivo es mover todos los discos de la varilla izquierda a la derecha, respetando una regla esencial: no se puede colocar un disco más grande sobre otro más pequeño.
Si aún no conoce este juego, solo le llevará un momento entender cómo funciona.
Con un poco de práctica, un niño inteligente y paciente de siete años puede lograrlo, y para una computadora es un ejercicio que no presenta ninguna dificultad. Cualquier estudiante de primer año de informática debería ser capaz de crear un programa que resolviera sistemáticamente el juego.
La probabilidad de que modelos como Claude u o3 alcancen algún día la inteligencia artificial general (AGI) parece, en el mejor de los casos, muy remota.
Gary Marcus
Sin embargo, los modelos más recientes, como Claude, ya tienen dificultades para resolver el problema con 7 discos, alcanzando menos del 80 % de precisión, y son prácticamente incapaces de hacerlo con 8 discos.
Apple ha constatado que ni siquiera el muy apreciado o3-min (high) lo hace mejor y ha observado resultados similares en otras tareas.
Es realmente vergonzoso que los LLM sigan sin poder resolver de forma fiable un problema tan trivial como la torre de Hanoi. ¡Y eso que hay numerosas bibliotecas de código fuente disponibles gratuitamente en internet!
¿Qué dice esto de la inteligencia de los LLM?
Si no se puede utilizar un sistema de IA de miles de millones de dólares para resolver un problema que Herbert Simon, uno de los verdaderos «padres fundadores» de la IA— resolvió en 1957 y que los estudiantes de primer año de inteligencia artificial resuelven sin problemas, entonces la probabilidad de que modelos como Claude u o3 alcancen algún día la inteligencia artificial general (AGI) 12 parece, en el mejor de los casos, muy remota.
Uno de los coautores de la investigación, Iman Mirzadeh, me llamó la atención sobre la sección 4.4 del artículo
Los investigadores habían proporcionado el algoritmo de solución al modelo, que solo tenía que seguir los pasos para resolver el problema. Sin embargo, incluso en este contexto, su rendimiento no había mejorado. Mirzadeh comentó esta paradoja de la siguiente manera: «Por lo tanto, nuestro argumento no es: ‘Los seres humanos no tienen límites, pero los modelos de razonamiento lingüístico (LRM) sí los tienen, por lo que no son inteligentes.’ Sino más bien: ‘lo que observamos en su razonamiento no se parece ni a un proceso lógico ni a una forma de inteligencia’».
El objetivo de la AGI no debería ser replicar perfectamente al ser humano, sino combinar lo mejor de ambos mundos: la adaptabilidad humana con la fuerza bruta y la fiabilidad computacional.
Gary Marcus
Usted dice haber observado un punto crítico en el artículo, ¿cuál es?
Se trata de una debilidad que ha sido bien expuesta por una cuenta anónima en X, que, en general, no es una fuente conocida por sus buenos argumentos…
Es la siguiente: los seres humanos comunes también tienen una serie de limitaciones, similares a las que ha puesto de manifiesto el equipo de Apple para los LLM. Muchas personas, aunque no todas, se equivocan al intentar resolver versiones de la torre de Hanoi con ocho discos.
Pero precisamente tenemos una respuesta a esta deficiencia. Inventamos las computadoras, y antes las calculadoras, precisamente para resolver de forma fiable problemas complejos, tediosos o de mayor o menor envergadura, como la torre de Hanoi.
El objetivo de la AGI no debería ser replicar perfectamente a los humanos, sino —como yo mismo he dicho a menudo— combinar lo mejor de ambos mundos: la adaptabilidad humana con la fuerza bruta y la fiabilidad computacional.
¿Cree que con los LLM corremos el riesgo de combinar lo peor de ambos mundos?
La visión que siempre he tenido de la AGI es la de un sistema que combina las fuerzas humanas y las de la máquina, al tiempo que supera las debilidades humanas. No me interesa una AGI incapaz de hacer una suma correcta. Y desde luego no querría confiar la infraestructura mundial o el futuro de la humanidad a un sistema así.
No queremos una AGI que se olvide de sumar una unidad en una operación elemental con el pretexto de que los humanos a veces cometen el mismo error. ¡Buena suerte en ese caso para conseguir una verdadera «alineación» o «seguridad» sin fiabilidad! 13
Por cierto, los modelos como o3 cometen errores mucho más a menudo debido a alucinaciones y tienen grandes dificultades para dibujar patrones fiables. Comparten algunas debilidades humanas, pero simplemente son peores en varios aspectos. Y si los humanos fallan, a menudo es por falta de memoria; los LLM, por su parte, disponen de gigabytes de memoria, por lo que no tienen excusa.
¿Cree que el entusiasmo por los LLM está desviando a la IA de su verdadero potencial científico, en particular, el de una alianza entre el razonamiento causal y la potencia de cálculo?
Lo que es evidente es que no vamos a «extraer el cono de luz» de la Tierra ni a «resolver la física», sea lo que sea lo que signifiquen estas pretenciosas declaraciones de Sam Altman, con sistemas incapaces de jugar al juego de la torre de Hanoi con ocho discos.
Cuando me preguntan por qué, al contrario de lo que se dice, me gusta la IA, y por qué creo que la IA —pero no la IA generativa— podría, a largo plazo, beneficiar profundamente a la humanidad, siempre cito el potencial de progreso científico y tecnológico que podríamos lograr si lográramos combinar las capacidades de razonamiento causal de nuestros mejores científicos con la potencia de cálculo bruta de las computadoras digitales modernas.
No queremos una IA que se olvide de sumar uno en una operación aritmética elemental con el pretexto de que los humanos a veces cometen el mismo error.
Gary Marcus
¿Cuáles serán las consecuencias de esta progresiva toma de conciencia de los límites de la actual generación de modelos?
Lo que muestra el documento de Apple, de manera fundamental —independientemente de cómo se defina la AGI—, es que los LLM no son un sustituto de los buenos algoritmos convencionales bien especificados.
Los LLM no saben jugar al ajedrez tan bien como los algoritmos clásicos, no pueden plegar proteínas tan eficazmente como algunos híbridos neurosimbólicos especializados, no gestionan las bases de datos tan bien como los motores diseñados para ello… En el mejor de los casos, que no siempre se alcanza, pueden escribir código Python, basándose en bloques de código simbólico externos para compensar sus propias debilidades, pero incluso eso no es fiable.
La principal consecuencia para las empresas y la sociedad que veo es la siguiente: no se puede simplemente «conectar» o3 o Claude a un problema complejo y esperar que funcione de forma robusta.
¿No estamos tratando de tranquilizarnos? El uso de los LLM nunca había sido tan grande. Ahora hay más gente usando ChatGPT que Wikipedia…
Como muestra el último artículo de Apple, los LLM pueden tener mucho éxito en una serie de pruebas sencillas, como la Torre de Hanoi con 4 discos, y dar la impresión de haber aprendido una solución generalizable, cuando en realidad no es así.
Al menos durante la próxima década, los LLM, con o sin «razonamiento» en el momento de la inferencia, seguirán siendo útiles, especialmente para el código, la lluvia de ideas y la redacción de textos. Y como me decía recientemente Rao: «El hecho de que los LLM/LRM no aprendan de forma fiable un único algoritmo subyacente no es un obstáculo absoluto para su uso. Veo los LRM como sistemas que aprenden a aproximarse al funcionamiento de un algoritmo ampliando progresivamente el razonamiento hasta la inferencia». En algunos contextos, esto es suficiente. En otros, no.
Pero cualquiera que piense que los LLM representan un camino directo hacia una AGI capaz de transformar radicalmente la sociedad para el bien común se engaña a sí mismo.
Esto no significa que las redes neuronales hayan muerto, ni que el deep learning haya llegado a su fin.
Los LLM son solo una forma posible de deep learning, y tal vez otras, especialmente aquellas que colaboran mejor con representaciones simbólicas, funcionen mejor en el futuro. El tiempo lo dirá.
Pero este enfoque actual tiene límites que cada día son más evidentes.
La IA no se está estrellando contra un muro.
Pero los LLM probablemente sí, o al menos están llegando a un punto de rendimientos decrecientes.
Necesitamos nuevos enfoques y diversificar las vías que se están explorando activamente.
Notas al pie
- Los Large Language Models son modelos de inteligencia artificial entrenados con grandes corpus de textos para generar, completar o analizar el lenguaje humano, basándose en correlaciones estadísticas entre las palabras.
- Mirzadeh, Iman, Oncel Tuzel, Keivan Alizadeh, Samy Bengio, Hooman Shahrokhi y Mehrdad Farajtabar. GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models. Apple, s. f.
- Gary F. Marcus, «Rethinking Eliminative Connectionism», Cognitive Psychology, Volumen 37, no. 3, 1998, pp. 243-282, ISSN 0010-0285.
- Gary F. Marcus, The Algebraic Mind Integrating Connectionism and Cognitive Science, MIT Press, 2001.
- Marcus, Gary F., S. Vijayan, S. Bandi Rao y Peter M. Vishton. «Rule Learning by Seven-Month-Old Infants.» Science 283, no. 5398 (1999): 77–80.
- Gary Marcus, Deep Learning: Critical Appraisal, 2018.
- Gary Marcus, «Deep Learning Is Hitting a Wall. What would it take for artificial intelligence to make real progress?», Nautilus, 10 mars 2022.
- Subbarao Kambhampati et al. Stop Anthropomorphizing Intermediate Tokens as Reasoning/Thinking Traces! School of Computing & AI, Arizona State University.
- Bhambri Siddhant, Upasana Biswas y Subbarao Kambhampati, Interpretable Traces, Unexpected Outcomes: Investigating the Disconnect in Trace-Based Knowledge Distillation.
- Valmeekam Karthik, Kaya Stechly, Atharva Gundawar y Subbarao Kambhampati. «A Systematic Evaluation of the Planning and Scheduling Abilities of the Reasoning Model o1.» Transactions on Machine Learning Research, abril de 2025.
- Juega a la Torre de Hanoi aquí.
- La AGI (Inteligencia Artificial General) se refiere a una forma de inteligencia artificial capaz de comprender, aprender y realizar cualquier tarea cognitiva que un ser humano pueda realizar, con un nivel de rendimiento igual o superior.
- La alineación en inteligencia artificial se refiere a garantizar que un sistema de IA persiga objetivos compatibles con las intenciones, los valores y los intereses de los seres humanos que lo utilizan o implementan.
