
Un articolo pubblicato questo fine settimana da Apple propone una quantificazione delle capacità di ragionamento dei modelli di linguaggio generativo (LLM) che sembrano crollare oltre un certo livello di complessità dei compiti. Diversi osservatori parlano di un duro colpo, un muro di complessità contro cui si scontra l’attuale generazione di modelli di linguaggio generativo (LLM) 1. Cosa ne pensa?
Non si tratta di un semplice duro colpo, ma di un vero e proprio KO, tanto più che questo articolo non è un caso isolato. Fa seguito a un’altra ricerca pubblicata lo scorso anno da molti degli stessi autori, che già dimostrava l’impossibilità di costruire agenti affidabili senza un ragionamento formale e astratto sufficientemente sviluppato 2.
Potrebbe riassumere brevemente l’argomento dell’articolo?
Apple ha testato le capacità di “ragionamento” delle attuali intelligenze artificiali, come ChatGPT, Claude o DeepSeek. Se tutti questi modelli sembrano intelligenti a prima vista, falliscono completamente non appena la complessità aumenta. La forza complessiva dell’argomentazione è innegabile: anche se c’è un’interessante debolezza nella nuova argomentazione, la conclusione è inequivocabile.
Nessuno dei modelli basati su LLM dimostra un vero ragionamento. Si tratta solo di sistemi di riconoscimento di modelli estremamente costosi che crollano non appena vengono confrontati con situazioni al di fuori della loro area di addestramento.
Si tratta di un vicolo cieco strutturale dei LLM per alcune applicazioni?
In effetti, tutte le ricerche serie dimostrano ormai che i grandi modelli linguistici non ragionano allo stesso modo degli esseri umani. Possono “riflettere di più”, ma solo fino a un certo punto.
Oltre una certa soglia, si arrendono rapidamente, anche se dispongono ancora di risorse di calcolo più che sufficienti.
Nessuno dei modelli basati su LLM dimostra un vero ragionamento.
Gary Marcus
Anche quando viene fornito loro l’algoritmo esatto da seguire, ovvero le regole per risolvere un compito complesso, questi modelli tendono a eseguirlo molto male. Ciò mette in luce una distinzione fondamentale: eseguire non significa comprendere.
Il problema non risiede in una mancanza di creatività, ma in un difetto logico fondamentale. I modelli tendono a “riflettere troppo” su problemi semplici e a provare risposte sbagliate anche dopo aver trovato quella giusta. E di fronte a problemi più difficili, riflettono meno. Il risultato è uno spreco di risorse di calcolo da un lato e un abbandono prematuro dall’altro.
Come si inserisce, secondo lei, questo nuovo studio nel dibattito sulla capacità dei LLM di generalizzare a situazioni radicalmente nuove?
Da un lato, questa ricerca fa eco e amplifica l’argomento sulla distribuzione dell’addestramento che sviluppo dal 1998: le reti neurali, in varie forme, possono generalizzare all’interno della distribuzione dei dati su cui sono state addestrate, ma le loro generalizzazioni tendono a crollare al di fuori di tale distribuzione.
Questo era il fulcro di un articolo che avevo pubblicato nel 1998, in cui criticavo i perceptron multistrato (multilayer perceptrons) — gli antenati degli attuali modelli linguistici — mostrando i loro fallimenti fuori distribuzione su semplici compiti di calcolo e previsione di frasi 3.
Esiste una distinzione fondamentale nell’IA generativa: eseguire non significa comprendere.
Gary Marcus
Questo è stato anche il tema centrale del mio primo libro, The Algebraic Mind (2001) 4, che ampliava questa critica, così come del mio primo articolo su Science (1999) 5, in cui dimostravo, attraverso un esperimento, che i bambini di sette mesi erano in grado di estrapolare in un modo che le reti neurali dell’epoca non erano in grado di replicare. Questo è stato anche il motivo principale alla base di Deep Learning: Critical Appraisal (2018) 6 e poi di Deep Learning is Hitting a Wall (2022) 7. Ho identificato questo limite ancora l’anno scorso come il punto debole più importante – e più importante da comprendere – dei modelli di apprendimento profondo.
Quindi è da un po’ di tempo che lavoro su questo argomento…
L’articolo si basa anche sul lavoro di Subbarao Kambhampati, ricercatore di informatica presso l’Arizona State University.
Sì, e voglio sottolinearlo. Questa ricerca non si limita a riprendere le argomentazioni sviluppate da Rao negli ultimi anni, ma le rafforza.
Si tratta delle critiche ai modelli cosiddetti di “ragionamento” e alle famose “catene di pensiero” (CoT) che producono, che sembrano molto meno solide di quanto si sostenga.
Per chi non ha familiarità con il concetto, una “catena di pensiero” è, in parole povere, ciò che il sistema sostiene di aver “ragionato” per arrivare a una risposta, nei casi in cui compie più fasi di riflessione. I “modelli di ragionamento” si riferiscono alla nuova generazione di tentativi di aggirare i limiti strutturali dei LLM, costringendoli a “ragionare” nel tempo, tramite una tecnica chiamata inference-time compute (calcolo al momento dell’inferenza).
Rao non è mai stato convinto da questa argomentazione.
Ha scritto una serie di articoli brillanti che dimostrano, tra l’altro, che le catene di pensiero generate dai LLM non sempre corrispondono a ciò che questi modelli fanno realmente. Recentemente, ad esempio, ha osservato che tendiamo a antropomorfizzare eccessivamente le tracce di ragionamento dei LLM, parlando di “pensiero” dove questo termine non sembra adeguato 8.
Un altro dei suoi recenti articoli mostra che anche quando le catene di ragionamento sembrano corrette, le risposte finali non lo sono necessariamente 9.
Rao è stato probabilmente il primo a dimostrare che uno di questi “modelli di ragionamento” — in questo caso o1 — soffriva del tipo di problema che il rapporto di Apple documenta oggi 10. Consiglio a tutti di leggere il suo lavoro.
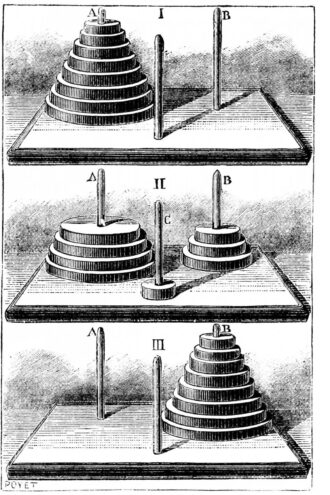
Il documento di Apple riprende la critica di Rao e la vostra, concentrandosi in particolare su un problema classico piuttosto semplice: la torre di Hanoi. Di cosa si tratta?
Si tratta di un gioco classico composto da tre aste e diversi dischi di dimensioni diverse 11. L’obiettivo è quello di spostare tutti i dischi dall’asta di sinistra a quella di destra, rispettando una regola fondamentale: non è consentito posizionare un disco più grande su uno più piccolo.
Se non conoscete ancora questo gioco, ci vuole solo un attimo per capirne il funzionamento.
Con un po’ di pratica, un bambino di sette anni intelligente e paziente può riuscirci, mentre per un computer è un esercizio che non presenta alcuna difficoltà. Qualsiasi studente al primo anno di informatica dovrebbe essere in grado di realizzare un programma in grado di risolvere sistematicamente il gioco.
La probabilità che modelli come Claude o o3 raggiungano un giorno l’intelligenza artificiale generale (AGI) sembra — nella migliore delle ipotesi — molto remota.
Gary Marcus
Tuttavia, i modelli più recenti come Claude hanno già difficoltà a risolvere il problema con 7 dischi —raggiungendo meno dell’80% di precisione — e sono praticamente incapaci di riuscirci con 8 dischi.
Apple ha scoperto che anche il molto apprezzato o3-min (high) non ha ottenuto risultati migliori e ha osservato risultati simili in diversi altri compiti.
È davvero imbarazzante che i modelli di linguaggio generativo non riescano ancora a risolvere in modo affidabile un problema così banale come la torre di Hanoi. E questo nonostante esistano numerose librerie di codice sorgente disponibili gratuitamente sul web!
Cosa dice questo dell’intelligenza degli LLM?
Se non è possibile utilizzare un sistema di IA da miliardi di dollari per risolvere un problema che Herbert Simon, uno dei veri “padri fondatori” dell’IA, risolse già nel 1957 e che gli studenti del primo anno di intelligenza artificiale risolvono senza problemi, allora la probabilità che modelli come Claude o o3 raggiungano un giorno l’intelligenza artificiale generale (AGI) 12 sembra — nella migliore delle ipotesi — molto remota.
Uno dei coautori della ricerca, Iman Mirzadeh, ha attirato la mia attenzione sulla sezione 4.4 dell’articolo
I ricercatori avevano fornito l’algoritmo di soluzione al modello, che doveva solo seguire i passaggi per risolvere il problema. Tuttavia, anche in questo contesto, le sue prestazioni non erano migliorate. Egli ha commentato questo paradosso come segue: “Il nostro argomento non è quindi: ‘Gli esseri umani non hanno limiti, ma i modelli di ragionamento linguistico (LRM) sì, quindi non sono intelligenti’. Ma piuttosto: ‘ciò che osserviamo nel loro ragionamento non assomiglia né a un processo logico, né a una forma di intelligenza’”.
L’obiettivo dell’AGI non dovrebbe essere quello di replicare perfettamente l’essere umano, ma di combinare il meglio dei due mondi: l’adattabilità umana con la forza bruta e l’affidabilità computazionale.
Gary Marcus
Lei dice di aver notato un punto critico nell’articolo, quale?
Si tratta di una debolezza che è stata ben esposta da un account anonimo su X — che in generale non è una fonte nota per le sue buone argomentazioni…
È la seguente: anche gli esseri umani comuni presentano una serie di limiti, simili a quelli evidenziati dal team Apple per gli LLM. Molte persone — non tutte — sbagliano quando cercano di risolvere versioni della torre di Hanoi con 8 dischi.
Ma proprio a questa lacuna abbiamo una risposta. Abbiamo inventato i computer — e prima ancora le calcolatrici — proprio per risolvere in modo affidabile problemi complessi, noiosi o di maggiore o minore entità, come la torre di Hanoi.
L’obiettivo dell’AGI non dovrebbe essere quello di replicare perfettamente l’essere umano, ma — come ho spesso affermato — quello di combinare il meglio dei due mondi: l’adattabilità umana con la forza bruta e l’affidabilità computazionale.
Pensa che con gli LLM si rischi di combinare il peggio dei due mondi?
La visione che ho sempre avuto dell’AGI è quella di un sistema che unisce le forze umane e quelle della macchina, superando al contempo le debolezze umane. Un’AGI incapace di fare una somma corretta non mi interessa. E non vorrei certo affidare l’infrastruttura mondiale o il futuro dell’umanità a un sistema del genere.
Non vogliamo un’AGI che dimentica di tenere conto di un’unità in una semplice addizione con la scusa che anche gli esseri umani a volte commettono lo stesso errore: in tal caso, buona fortuna per ottenere un vero “allineamento” o “sicurezza” senza affidabilità 13!
Tra l’altro, modelli come o3 commettono molto più spesso errori dovuti all’allucinazione e hanno grandi difficoltà a disegnare schemi affidabili. Condividono alcune debolezze umane, ma sono semplicemente meno bravi sotto diversi aspetti. E se gli esseri umani falliscono, spesso è per mancanza di memoria; i LLM, invece, hanno gigabyte di memoria, quindi non hanno scuse.
L’entusiasmo intorno ai LLM le sembra distogliere l’IA dal suo vero potenziale scientifico — ovvero quello di un’alleanza tra ragionamento causale e potenza di calcolo?
Ciò che è evidente è che non “estrarremo il cono di luce” dalla Terra né “risolveremo la fisica”, qualunque cosa significhino queste affermazioni presuntuose di Sam Altman, con sistemi incapaci di giocare alla Torre di Hanoi con 8 dischi.
Quando mi chiedono perché — contrariamente a quanto si dice — amo l’IA e perché penso che l’IA — ma non l’IA generativa — potrebbe, a lungo termine, portare enormi benefici all’umanità, cito sempre il potenziale di progresso scientifico e tecnologico che potremmo raggiungere se riuscissimo a combinare le capacità di ragionamento causale dei nostri migliori scienziati con la potenza di calcolo bruta dei moderni computer digitali.
Non vogliamo un’IA che dimentichi di tenere conto di un’unità in una somma elementare con la scusa che anche gli esseri umani a volte commettono lo stesso errore.
Gary Marcus
Quali saranno le conseguenze di questa progressiva presa di coscienza dei limiti dell’attuale generazione di modelli?
Ciò che il documento di Apple dimostra in modo fondamentale — indipendentemente da come si definisca l’AGI — è che gli LLM non sono un sostituto dei buoni algoritmi convenzionali ben specificati.
Gli LLM non sanno giocare a scacchi bene come gli algoritmi classici, non possono ripiegare le proteine in modo efficiente come alcuni ibridi neurosimbolici specializzati, non gestiscono i database bene come i motori progettati per questo scopo… Nel migliore dei casi — che non sempre si verifica —, possono scrivere codice Python, basandosi su blocchi di codice simbolico esterni per compensare le proprie debolezze — ma anche questo non è affidabile.
La principale conseguenza per le aziende e la società che vedo è la seguente: non si può semplicemente “collegare” o3 o Claude a un problema complesso e aspettarsi che funzioni in modo affidabile.
Non stiamo cercando di rassicurarci? L’uso dei LLM non è mai stato così diffuso. Ora più persone usano ChatGPT che Wikipedia…
Come dimostra l’ultimo articolo di Apple, gli LLM possono ottenere ottimi risultati in una serie di test semplici — come la Torre di Hanoi a 4 dischi — e dare l’illusione di aver appreso una soluzione generalizzabile, quando in realtà non è affatto così.
Almeno per il prossimo decennio, gli LLM — con o senza “ragionamento” al momento dell’inferenza — continueranno ad essere utili, in particolare per il codice, il brainstorming e la redazione di testi. E come mi diceva recentemente Rao: “Il fatto che gli LLM/LRM non imparino in modo affidabile un unico algoritmo sottostante non è un ostacolo assoluto al loro utilizzo. Vedo gli LRM come sistemi che imparano ad approssimare il funzionamento di un algoritmo allungando progressivamente il ragionamento fino all’inferenza”. In alcuni contesti questo è sufficiente. In altri no.
Ma chiunque pensi che gli LLM rappresentino una via diretta verso un’AGI in grado di trasformare radicalmente la società per il bene comune si sta illudendo. Ciò non significa che le reti neurali siano morte, né che il deep learning sia giunto al termine.
Gli LLM sono solo una forma possibile di deep learning, e forse altre forme, in particolare quelle che collaborano meglio con le rappresentazioni simboliche, avranno più successo in futuro. Il tempo lo dirà.
Ma l’approccio attuale ha dei limiti che diventano ogni giorno più evidenti.
L’IA non sta sbattendo contro un muro.
Ma gli LLM probabilmente sì — o almeno stanno raggiungendo un punto di rendimento decrescente.
Abbiamo bisogno di nuovi approcci e di diversificare le strade che vengono attivamente esplorate.
Note
- I Large Language Models sono modelli di intelligenza artificiale addestrati su vasti corpora di testi per generare, completare o analizzare il linguaggio umano, basandosi su correlazioni statistiche tra le parole.
- Mirzadeh, Iman, Oncel Tuzel, Keivan Alizadeh, Samy Bengio, Hooman Shahrokhi, et Mehrdad Farajtabar. GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models. Apple, n.d.
- Gary F. Marcus, «Rethinking Eliminative Connectionism», Cognitive Psychology, Volume 37, Issue 3, 1998, Pages 243-282, ISSN 0010-0285.
- Gary F. Marcus, The Algebraic Mind Integrating Connectionism and Cognitive Science, MIT Press, 2001.
- Marcus, Gary F., S. Vijayan, S. Bandi Rao, and Peter M. Vishton. “Rule Learning by Seven-Month-Old Infants.” Science 283, no. 5398 (1999): 77–80.
- Gary Marcus, Deep Learning: Critical Appraisal, 2018.
- Gary Marcus, «Deep Learning Is Hitting a Wall. What would it take for artificial intelligence to make real progress?», Nautilus, 10 mars 2022.
- Subbarao Kambhampati et al. Stop Anthropomorphizing Intermediate Tokens as Reasoning/Thinking Traces! School of Computing & AI, Arizona State University.
- Bhambri Siddhant, Upasana Biswas et Subbarao Kambhampati, Interpretable Traces, Unexpected Outcomes: Investigating the Disconnect in Trace-Based Knowledge Distillation.
- Valmeekam Karthik, Kaya Stechly, Atharva Gundawar et Subbarao Kambhampati. “A Systematic Evaluation of the Planning and Scheduling Abilities of the Reasoning Model o1.” Transactions on Machine Learning Research, avril 2025.
- Giocare alla torre di Hanoi qui.
- L’AGI (Artificial General Intelligence) indica una forma di intelligenza artificiale in grado di comprendere, apprendere e svolgere qualsiasi compito cognitivo che un essere umano può realizzare, con un livello di prestazioni uguale o superiore.
- L’allineamento, in intelligenza artificiale indica il fatto di garantire che un sistema di IA persegua obiettivi compatibili con le intenzioni, i valori e gli interessi degli esseri umani che lo utilizzano o lo implementano.
